テスト自動化をするにあたって、「どの(機能の、区分の etc…)テストを自動化すればいいのか」「どうやって選べばいいのか」という悩みをよく聞きます。
テスト自動化に慣れていると多少経験的に「こうかな」とアタリをつけられると思うのですが、じゃあ慣れるまでどうするのか問題が残ります。
いくつか世に公開されている「こう選ぶとよい」という方法があるので、今回はそのうちのひとつ、TestAutomationUなどで有名なAngie Jonesのスライドに記載された方法を紹介します。
元ネタはこちら
プレゼン動画はこちら
上の2つで理解できる方はこの記事不要です。
本記事の画像は上記のAngieのスライドより引用しています。
自動化対象を選ぶ方法の概要
スライドではTwitterの機能を例に説明されています。
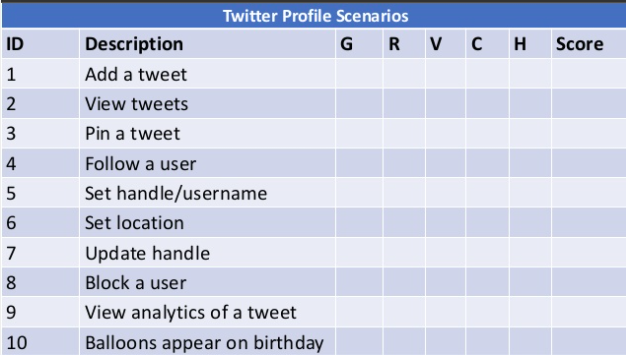
表の右半分、G, R, V, C, Hを設定してそこからScoreを算出します。
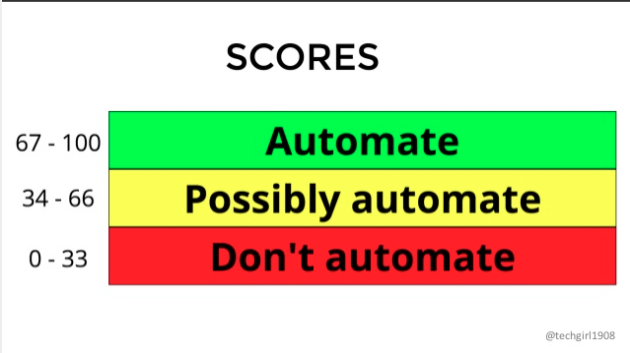
スコアが67~100だったら自動化する、34~66だったら自動化できそう、0~33だったら自動化しない。という基準です。
自動化対象を選ぶ方法の詳細
順を追って見ていきましょう。
1. Gut Feeling(直感)の設定
まずG列は、直感で自動化する/しないを入れていきます。
例えばアプリケーションのコアの機能で、これがなかったら価値がゼロになる、というような機能の場合は直感的に自動化「する」に設定する。
一方そんなに大事じゃない、なくてもユーザーがものすごく困ることはないかな、くらいの機能の場合は「しない」に設定する。などです。
リスクや価値などはこの先のステップでも細かく見ますが、ここはあくまでも直感なのでエイヤで埋めるところです。
2. RISK(リスク)の設定
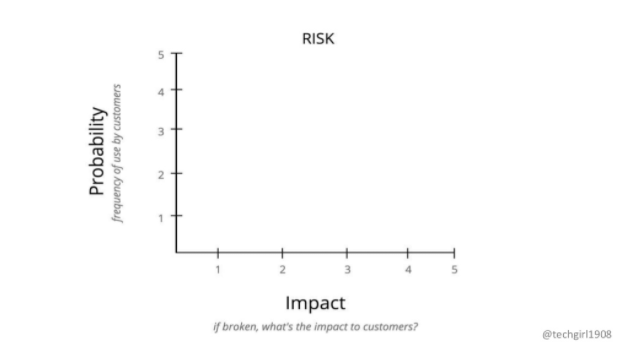
リスクはProbability(顧客の使用頻度)とImpact(もし壊れた場合に顧客に与える影響)をそれぞれ5段階で評価し、掛け算したものがスコアになります。
3. VALUE(価値)の設定
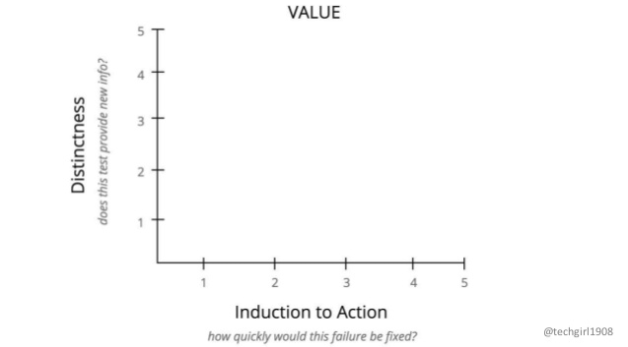
価値はDistinctness(テストすることで新たな情報が得られるか)とInduction to Action(どのくらい速く故障が修正されるか、バグがあったぞとなったときに開発者がどのくらい急いで直すか)とをこちらも5段階評価し、掛け算したものがスコアになります。
Distinctnessが若干わかりづらいですが、講演動画の中ではSet handles/usernameとUpdate handleを比べて、UpdateのほうがSetよりもDistinctnessが低い=テストすることで新たな情報が得られる度合いはUpdateのほうが低い、と設定しています。直感にはあっているように思います。
4. COST-EFFICIENCY(費用対効果)の設定
コスパ、のほうが表現的にしっくりくるかもしれません。
Quickness(どのくらいすぐ自動化できるか)と、Ease(どのくらい容易に自動化できるか)の5段階評価の掛け算です。
5. HISTORY(過去の状況)の設定
Similar to weak areas(関連するエリアで過去どのくらい故障があったか)と、Frequency of breaks(このテストで過去どのくらい故障が見つかったか)の5段階評価の掛け算です。
講演では過去のバグのバックログから情報を取ってきて評価する、と言っています。
たとえば以下のようなバグのデータがあったとします。各エリアで過去あったバグの数、おそらくチケット数カウントかと思いますが、データを集計してきたもの、です。(もちろん架空とのこと。)
| Area | # |
|---|---|
| setting location | 51 |
| updating handle | 27 |
| editing location | 60 |
| pinning tweet | 2 |
| viewing tweets | 10 |
たとえばAdd a tweet機能に対して評価をしようと思った場合、類似のフィーチャーでのバグというのは上記の表にないですし、かつAdd a tweet機能そのもののバグもありません。つまりHistoryはゼロ、となります。 (講演を見ていて、1~5の5段階じゃなかったのか・・・と突っ込みたくなりましたが、もしゼロを除いても1になるので、大勢に影響はなさそうです。)
一方でPin a tweetやView tweets機能はそれぞれバグのデータ表に2と10の記載があるので、5段階評価ではFrequency of breaksが1や3、と判断しています。
6. トータルのScore算出
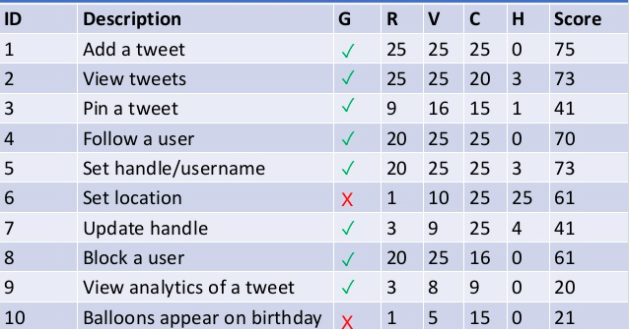
G, R, V, C, Hをすべて設定したら、R~Hの値を足して機能ごとの自動化スコアを算出します。
あとは先に出した区分に沿って、
- 自動化する
- できたらする
- しない
の3つにわけます。
緑黄赤に色分けをしたものが以下。
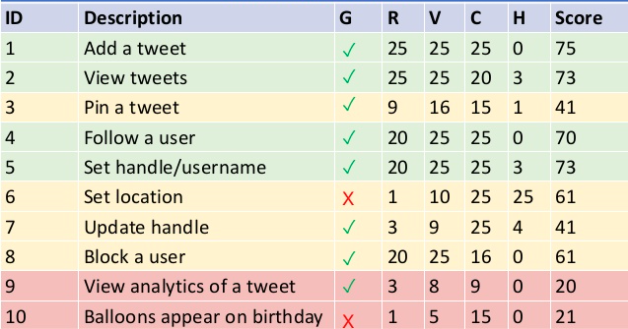
最初に直感でやる/やらないを設定したG列と、最終スコアから判断した結果(緑黄赤)とは必ずしも一致していないことがわかりますね。
まとめ
言ってしまえばどこを自動化するか(しないか)は決めの問題でもあるので、チーム内で合意が出来ればそれで良い、とも言えます。
ただ、なんとなくで決めているとうまくいかないですし、効果が薄いところに時間をかけて自動化する危険もあります。
今回のやり方をすれば、5段階評価の中に主観も多分に含まれるものの、一定「みんなが納得できそうな」方法でスコア算出&範囲決定ができそうです。