読もうと思ったきっかけ、参照していたもの
A Survey of Flaky Tests | ACM Transactions on Software Engineering and Methodologyを先に読み始めて、参照されていたので気になった。
メモ
論文の概要
- Flakyテストは辛い。一般的な対策は、失敗したテストを再実行すること。
- しかし、再実行はコストがかかる
- そこで、テストを何度も再実行するのではなく、効率的に、Flakyテストを見つける技術およびそのツールを作って効果検証した
- 結果、検証用のデータにおいて、Flaky検出率は95%、誤ってFlakyと判断したものは1.5%という結果が得られた
- モノはこれ
背景
- Flakyなテストで困っている人は多い
- 論文中では、色々なプロジェクト・研究者のところでの結果が出ており、5%, 13%, 半分、など無視できないレベル
- テストが失敗したときにFlakyかどうかを確かめるにはRerun(再実行)が行われるのが一般的
- しかし、失敗したテストを再実行していると、コストがかかりすぎる
- mavenのFlaky対策の仕組み(※おそらくこれのこと:Maven Surefire Plugin – Rerun failing tests)を使っても、Flakyテストのうち23%しか検出できない
手法
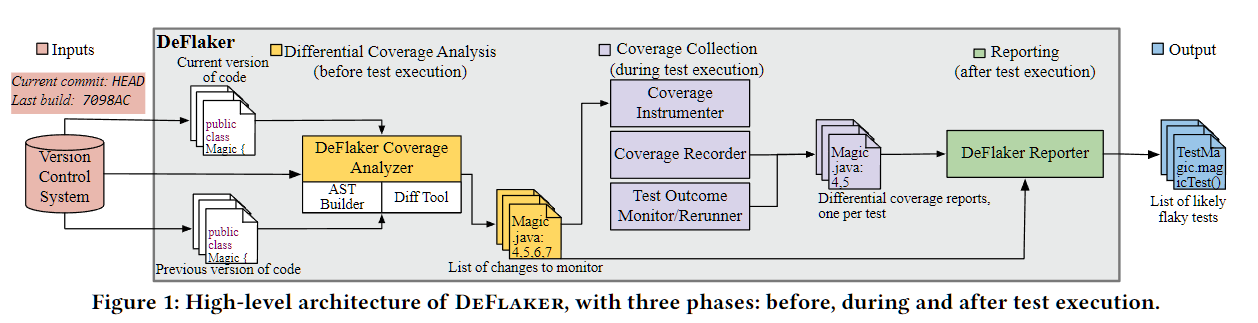
DeFlakerという手法及びツールを実現した。
- ソースコードに対して前バージョンのものとの差分をとり、差分がある箇所を実行しているテストを区別
- 変更箇所を参照していないテストがFailしたら、Flakyと言える
- このとき、単純に文だけで差分をとると高コストになるので、テストがそのクラスを参照する場合は、テストがそのクラスをカバーしているとみなした
- これを、本研究ではHybridな手法と呼んでいる(StatementとClass)
- 上の図中でもあるように、ASTでの比較などいくつか効率化の工夫をしている
- バイトコードにプローブを挿入するが、テスト対象への悪影響が少ない
- 以下の基準でFlakyかどうかを判定
- 前はPassしていたのに今回Failで、かつコード変更箇所をカバーしていない
- 今回Failして、同じコードで再実行してPassした場合
- ↑つまり、失敗箇所を全部再実行、としなくともよい
結果
ReserchQuestionは以下
- 従来の、再実行するやり方と比べてどのくらいFlakyテストを検知できるか
- DeFlakerがFlakyと判断したものは実際どのくらいFailするのか
- クラスレベルの検出方法と比べてHybridな方法はどのくらい優れているのか
- DeFlakerをすべてのテストについて行った場合のオーバーヘッドはどのくらいか
調査結果
- DeFlakerのほうが再実行よりも基本的には多くのFlakyテストを見つけられている。例外は、再実行のたびにJVMを再起動する方法で再実行した場合のみ。ただしこのやり方はコストが高すぎる。
- Flaky検出率は95%、誤ってFlakyと判断したものは1.5%
- HybridなアプローチのほうがFlakyテストを検知できた。調査した対象トータルで、Hybridは88%、Classのみのアプローチでは77%
- DeFlakerを使った場合は、何もカバレッジツールを使わなかった場合と比べて平均4.5%なので、影響は少ないと言える
感想
Flakyテストを機械的に検出しよう、というのは自分はやったことがなかったので、とても興味深く読んだ。
コード変更箇所をただ探してテストが通るかどうかを見るのは高コスト、という話はなるほど確かに。今回の手法は精度を犠牲にしすぎず、かつ現実的なコストで行えるようにしたというのが面白かった。
次に気になっているもの
順序依存のFlakyなテストを自動修復するらしい